En los últimos meses, las grandes empresas de tecnología han anunciado y lanzado sus propias versiones de inteligencia artificial generativa. En junio, Tim Cook anunció el lanzamiento de Apple Intelligence para las próximas versiones de los sistemas operativos de sus dispositivos. Apenas ayer, 23 de julio, Meta puso a disposición Meta AI en sus aplicaciones Facebook, Instagram, WhatsApp y Messenger en varios países de latinoamérica. Por su lado, Google desarrolló Gemini, la cual busca integrar a sus diferentes productos y plataformas.
Al día de hoy es prácticamente imposible no haber escuchado de ChatGPT. En clase, en el trabajo o mientras navegamos en nuestra red social favorita hemos visto distintas historias de cómo utilizar esta nueva herramienta para simplificar nuestro trabajo, generar contenido y un sinfín de aplicaciones. Sin embargo, en muchos casos, se está generando una percepción errónea sobre las verdaderas capacidades de ChatGPT.
Para ello, abordaremos, en primer lugar, un poco de la historia y algunos conceptos fundamentales de esta tecnología en tendencia. Posteriormente tocaremos otros temas como la regulación, los mecanismos de moderación para evitar «contaminar» la herramienta y otros posibles impactos de esta tecnología en diversos sectores. Leer más
En muchas oportunidades, al momento de navegar en línea, nos hemos encontrado con recomendaciones sobre qué vídeos ver, qué páginas visitar, a qué personas seguir, qué música escuchar o qué noticias leer. En la mayoría de casos, el objetivo principal de estas plataformas es mantener la atención de las personas tanto tiempo como sea posible dentro de sus dominios, ya sean aplicativos o páginas web. En un contexto electoral, ¿cuál es la relevancia de estas sugerencias? ¿Hacia dónde nos conducen estas recomendaciones? ¿Cuál es el rol de la tecnología? ¿Es posible liberarnos de estos sistemas?
Los periodos electorales traen consigo un conjunto de interacciones muy particulares entre las personas. Por ejemplo, se extienden los espacios de diálogo, se escuchan propuestas de cambio, pero lo más resaltante es la cobertura de propaganda política que ataca desde los espacios más tradicionales como radio y televisión hasta los más recientes como redes sociales. Básicamente, en este periodo, las personas están expuestas a estrategias, campañas y discursos con el objetivo de captar la mayor cantidad de votos. Muchas de estas estrategias se han posicionado en las redes sociales, ya que han tenido un rol fundamental en la manera en que los partidos políticos han interactuado con su público objetivo, especialmente debido a restricciones de reunión masiva a causa del COVID-19.
Este nuevo espacio de interacción en los dominios de las plataformas de redes sociales tiene mecánicas muy diferentes a aquellas que ocurre en el espacio analógico. Por ejemplo, en las redes, mencionamos un interés en común de las plataformas por la atención y tiempo del usuario, y para que esto sea posible las personas deben recibir estímulos positivos durante su navegación en estas plataformas. Los estímulos pueden variar entre mensajería, likes, comentarios afirmando posturas o en contra de una diferente, etc. En el espacio analógico, reunir a estas personas y generar este tipo de estímulos es muy complicado, mientras que las redes sociales no solo permiten un mayor alcance sino que tienen la capacidad de generar estas reacciones positivas de manera casi instantánea, en cualquier momento y desde cualquier lugar en el que se encuentren las personas.
Otra característica inherente a estas plataformas es su capacidad de almacenar todo tipo de interacciones de sus millones de usuarios. El gran volumen de estos datos, complementados con técnicas de análisis basadas en inteligencia artificial, le dan la posibilidad a la plataforma de mostrar a sus usuarios contenido con el que más se sientan a gusto o contenido con el que existe mayor probabilidad de interactuar.
Es en este punto donde se discute el impacto de estos algoritmos de recomendación, ya que las creencias y pensamientos de las personas pueden ser conducidos poco a poco a versiones más extremas o radicalizadas que generarían una división mucho más marcada entre grupos contrarios. Sin embargo, también es importante reconocer que la existencia de agrupaciones y movimientos asociados a formas de pensamiento, tradiciones, gustos o preferencias se da desde mucho tiempo antes de la aparición de internet, redes sociales u otras tecnologías con las que hoy convivimos e interactuamos.
Estos espacios digitales aislados y compuestos por contenido afín a las creencias de las personas y otros usuarios con comportamiento similar son las llamadas cámaras de eco o también filter bubbles. El problema con estos espacios ha sido estudiado y analizado desde incluso antes de la revolución de internet: se caracterizan por desarrollar sus propias reglas, sus propias fuentes de información y lenguaje donde cualquier punto de vista distinto es desacreditado con hostilidad. Algunas plataformas optaron por incluir fact-checkers sobre algunos temas en específico, añadiendo un etiquetado a sus contenidos. Sin embargo, se ha visto que este etiquetado también genera, en grupos más radicalizados, la sensación de que la plataforma ha elegido un bando específico.
Afortunadamente, muchas de estas plataformas ponen algunos datos a disposición a través de APIs, de manera que es posible analizar y visualizar el comportamiento de cierto grupo de usuarios en estas redes. Son estas visualizaciones las que nos muestran clusters de personas agrupadas por un interés, afinidad o comportamiento muy similar en estas plataformas.
Hemos hablado de cómo las tecnologías de los últimos 10 años han contribuido con el entorno de identidad digital en el Perú, pero es imposible ignorar la evolución de la tecnología en el campo de los teléfonos inteligentes (smartphones). Actualmente los smartphones tienen tanta capacidad de procesamiento como una computadora personal. Esto ha permitido que tecnologías como reconocimiento facial o de huellas dactilares sean posibles y se muestran como alternativas al DNIe en entornos digitales para la autenticación. Esto es posible también porque RENIEC guarda en su base de datos fotografías de nuestro rostro y nuestras huellas dactilares que pueden pasar por un proceso para clasificar nuestras características biométricas.
Entonces sería posible desarrollar una aplicación móvil capaz de reconocer algún patrón como nuestro rostro o nuestra huella dactilar, identificar sus parámetros biométricos, compararla con la existente en la base de datos del RENIEC y darnos acceso a diferentes servicios que tengan disponible. Como resultado, RENIEC ha desarrollado diversas herramientas móviles (apps) que permiten acceder a servicios muy parecidos a los que ofrece el Portal del Ciudadano.
El pasado 3 de abril se publicó en Business Insider que un usuario de un foro de hacking compartió información personal de más de 500 millones de usuarios de Facebook, incluyendo números de teléfono, correos electrónicos, última localización, estado sentimental y algunos datos más. Es importante prestar atención a este tipo de situaciones porque esta información puede ser utilizada para fines políticos, comerciales o suplantación de identidad, por ejemplo.
Una manera de comprobar si nuestro número de teléfono ha sido parte de ese filtrado de datos es haciendo uso de HaveIBeenPwned ingresando nuestro número de teléfono en formato internacional. Esto quiere decir que si nuestro número en Perú es 987654321, debemos agregarle el +51 por delante y hacer la consulta como se muestra en la imagen. Puedes consultar el código de tu país en esta web.
De acuerdo al informe que publicamos hace unos meses, se define Identidad Digital como el conjunto de mecanismos utilizados para verificar la identidad de una persona en un entorno digital. Para los ciudadanos, estos entornos serían principalmente páginas web o aplicaciones móviles. Entonces nos podríamos plantear las siguientes preguntas: ¿Qué me hace único como persona? y ¿quién decide o de quién depende afirmar que realmente soy yo la persona que está utilizando una web o aplicación? Antes de entrar en el contexto peruano y su infraestructura de Identidad Digital, respondemos a la primera pregunta.
Existen características físicas y biológicas que nos diferencian de otras personas. Por ejemplo, podríamos pensar en nuestra estatura, color de ojos o algunas manchas en nuestra piel. Sin embargo, el problema con estas características es que a pesar de parecer únicas en nuestro entorno, otras personas también las pueden tener. Por otro lado, existen características que realmente nos hacen únicos y que se utilizan en todo el mundo para identificar a personas de manera individual. Algunos ejemplos son nuestras huellas dactilares, nuestro rostro o nuestra voz. Este conjunto de características están clasificadas como datos biométricos, que a pesar de no ser los únicos son los más utilizados por los sistemas computacionales a nivel global.
En el Perú, el Registro Nacional de Identificación y Estado Civil (RENIEC) es la institución encargada de organizar y mantener el registro único de identificación de las personas, y por lo tanto, se encarga también de emitir el Documento Nacional de Identidad (DNI) que acredita la identidad de las personas. La importancia de RENIEC en el contexto de identidad digital se debe a que también tiene la facultad de emitir certificados digitales para personas naturales o jurídicas que lo soliciten. Estos certificados digitales vendrían a ser un análogo del DNI o del pasaporte en un entorno digital; dándonos la seguridad de que el intercambio de información es entre personas o entidades que realmente son quien dicen ser y que la comunicación entre ellos estará segura y protegida. Este sistema de certificados digitales es válido y confiable porque es parte de una infraestructura más grande y compleja que involucra hardware, software, políticas y procedimientos de seguridad que tienen como base la criptografía asimétrica. Esta infraestructura se llama Infraestructura de Clave Pública PKI por sus siglas en inglés (Public Key Infraestructure).
Con la tecnología de los últimos diez años y teniendo como referencia la implementación de identidad digital en otros países, en el Perú se desarrollaron diferentes plataformas o soluciones orientadas al ciudadano para acelerar procesos o trámites que en persona tomarían días o debían seguir un proceso burocrático muy lento y agotador. Esto aprovechando nuestros datos biométricos o certificados digitales en caso contemos con ellos. A continuación, describimos algunos proyectos desarrollados por el estado que serían parte del primer lote de soluciones de identidad digital orientado a los ciudadanos.
DNI electrónico
El DNI electrónico o DNIe también es emitido por RENIEC y su principal diferencia con el DNI convencional es que es una tarjeta inteligente que contiene un chip que almacena nuestros certificados digitales – emitidos también por RENIEC- que nos permite identificarnos en diferentes plataformas y firmar documentos de manera digital. El DNIe no se adquiere por defecto sino que es únicamente expedido a solicitud de las personas interesadas.
Los certificados vencen cada dos años y pueden ser renovados sin necesidad de renovar el DNIe completamente. Al tener un dispositivo físico que almacena de manera segura nuestros certificados digitales, tendríamos la posibilidad de identificarnos, en un entorno digital, ante cualquier entidad que haya implementado lo necesario para validar esta conexión, como es el caso del Portal del Ciudadano, que analizaremos más adelante. Idealmente serán entidades del gobierno que están interconectadas con RENIEC.
Haber apostado por una tecnología de tarjetas inteligentes como medio de identificación en medios digitales, implica que las personas debemos cumplir con un conjunto de condiciones para hacer uso de ella.
Un lector de tarjeta inteligente.
Una computadora con sistema operativo Microsoft Windows 7, 8 o 10 (32 bits o 64 bits).
Java JRE 8 (32 bits o 64 bits)
Portal del Ciudadano
El Portal del Ciudadano podría ser la plataforma con mayor publicidad de parte de RENIEC como muestra de los avances en identidad digital en los últimos años. Esta plataforma cubre muchas necesidades de las personas como trámites o acceso a información importante.
Inscribir el nacimiento de tu hijo o solicitar duplicado de su DNI.
Acceso a información pública.
Trámite de inscripción de nacimiento de hijo.
Solicitar la devolución de tasas pagadas y no utilizadas.
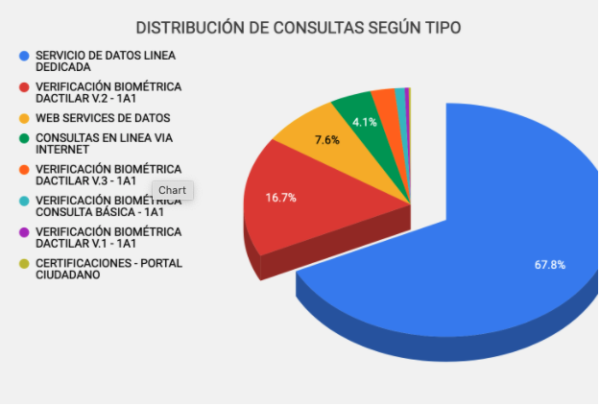
A diferencia de la mayoría de secciones que son opciones para hacer trámites y gestionarlos desde la plataforma, la opción de saber quién consultó nuestros datos RENIEC es una alternativa con mucho poder desde el punto de vista de transparencia y privacidad de nuestra información. La sección que muestra las personas que han consultado la ficha RENIEC del usuario también nos dice a qué institución pertenecen, la fecha de la consulta y el medio por el cual accedieron a esos datos. Un grupo de 5 personas colaboraron de manera voluntaria con nosotros dándonos acceso a esta lista y como resultado se presenta el siguiente gráfico a partir del tipo de consulta que se realizó sobre sus datos personales entre el año 2017 y febrero del 2020 previo al confinamiento por pandemia.
Esto muestra un gran porcentaje de consultas provenientes del servicio de datos por línea dedicada. Este es un servicio de RENIEC donde cualquier persona jurídica puede acceder a nuestros datos haciendo un pago correspondiente. Otro gran porcentaje de consultas se deben a consultas de verificación biométrica que pueden ser tomadas en aeropuertos, al firmar un acuerdo notarial o cuando solicitamos una nueva licencia de conducir.
Una observación importante a tener en cuenta para el uso del Portal del Ciudadano es que los requisitos para tener acceso a esta información son muy específicos al punto que llegaría a ser restrictivo como el uso del sistema operativo Windows, o una versión puntual de los drivers a instalar. Para una persona con capacidad promedio de uso de tecnologías, le sería complicado y confuso el proceso para configurar, instalar y acceder a esta información.
ID Perú – Plataforma de autenticación de la Identidad Digital Nacional
Esta plataforma pretende ser un espacio único donde los ciudadanos con DNIe accedan a servicios desarrollados por el estado o por desarrolladores autorizados en cuyo proceso deban utilizar el DNIe. La propuesta de esta plataforma es permitir desarrollar soluciones que involucren DNIe de una manera más simple en las distintas entidades del estado, poniendo a disposición demos y código fuente ejemplo para distintos lenguajes de programación.
Una de las medidas adoptadas a nivel mundial para prevenir la propagación del COVID-19 es el distanciamiento social. Como resultado de esta medida, muchas actividades se trasladaron al espacio digital como clases, reuniones de trabajo o incluso eventos sociales como celebraciones de cumpleaños o reuniones familiares. Por eso, hoy plataformas como Zoom, Google Meet, Microsoft Teams diseñadas originalmente para entornos laborales o empresariales han terminado ocupando un rol central en nuestra vida diaria. Lamentablemente, este nuevo espacio de interacción social también ha traído consigo algunos inconvenientes como invitados no deseados, comentarios agresivos en transmisiones en vivo, e incluso acoso en estos eventos.
Las empresas desarrolladoras de estas aplicaciones/plataformas están tomando rápidamente conciencia de estos problemas. En los meses recientes, han empezado a brindarnos una gama de posibilidades para prevenir estas situaciones y proteger a nuestros invitados. Por eso, antes de pensar que una aplicación es mejor que otra, es importante entender las limitaciones y diferencias de cada una. Por eso, si en algún momento te toca organizar una llamada o evento en línea, te dejamos nuestras recomendaciones a seguir antes y durante la llamada.Leer más
Desde el lanzamiento de la aplicación “Perú en tus Manos” (PETM), en Hiperderecho hemos hecho seguimiento a su desarrollo desde diferentes puntos de vista. Por un lado, se ha cubierto a nivel legal temas como la privacidad y la transparencia en la creación y despliegue de este tipo de tecnologías. También, aunque con menor detalle, hemos analizado críticamente las funciones técnicas de la aplicación y otros posibles desarrollos. En este artículo queremos profundizar aún más en este ámbito, principalmente para dejar en claro qué información de sus usuarios recoge esta aplicación, cómo lo hace y hacia dónde la envía.
El caso de PETM es interesante porque se presenta como una herramienta de información para los ciudadanos, pero también como un instrumento para que el gobierno pueda tomar decisiones. Para lograr ambos objetivos, la tecnología base con la que funciona este aplicativo es el GPS, que ya hemos analizado en una publicación anterior, señalando sus ventajas y desventajas.
A diferencia de propuestas en otros países como Italia, India, Reino Unido o República Checa, la aplicación peruana no es de código abierto. Es decir, el Gobierno no ha puesto a disposición del público el código fuente que hace posible la aplicación, haciendo difícil entender de primera mano cómo funciona y poder colaborar con mejoras o notificar de errores en el código. A pesar de esta limitación, gracias a que PETM ha sido desarrollada también para Android de manera nativa, es posible entender hasta cierto punto cuál es su arquitectura e incluso ver parte de su código fuente. El procedimiento que seguimos para obtener estos datos fue obtener el archivo APK de la aplicación desde una de muchas páginas que ofrecen este servicio. Luego de un proceso de decompilación, haciendo uso de la herramienta apktool, fue posible acceder a archivos fundamentales para el desarrollo del aplicativo como es el MANIFEST y algunas clases que contienen parte del código fuente de la aplicación.
En el artículo anterior de esta serie vimos las desventajas tanto de precisión como de consumo de energía del GPS y la triangulación. Además del evidente impacto en la privacidad y seguridad de las personas sometidas al monitoreo constante del gobierno. Frente a estas desventajas, se ha discutido una idea aparentemente innovadora que podría resolver todos los problemas anteriores: usar Bluetooth.
A diferencia del GPS, las aplicaciones basadas en Bluetooth tienen las siguientes ventajas:
Son más precisas en el trabajo de identificar un dispositivo cercano
Pueden funcionar en entornos cerrados donde la señal móvil es un problema como edificios o estacionamientos subterráneos
No necesitan estar conectado a una red o a Internet todo el tiempo para funcionar
No recogen la información de la localización geográfica ni el recorrido de sus usuarios
No consumen mucha energía del equipo
¿Pero cómo funciona una app de rastreo de contactos basada en Bluetooth? La propuesta de la mayoría de apps y plataformas que la han implementado o piensan hacerlo es la siguiente. Cada teléfono tiene asignado un identificador único que se emite mediante la señal Bluetooth, de tal manera que otro teléfono pueda «escuchar su identificador» cuando lo tenga cerca. Algo así como si cada teléfono gritara un pseudónimo de su dueño mientras este va por la calle. De esta manera, cada vez que un dispositivo detecte una señal cercana (o sea, escuchen los “gritos” de otro teléfono), almacenarán dicho identificador localmente, formando poco a poco un historial de todos los teléfonos, y por lo tanto personas, que han estado cerca del usuario.
Desde que se conoció el primer caso de Covid-19 en Perú, han surgido múltiples ideas de aplicaciones móviles (apps) para entender y contener el impacto que tiene el virus entre nosotros. Una de las ideas más populares es la del uso de tecnologías de seguimiento o tracking para rastrear a los contagiados, supervisar el cumplimiento de la orden de aislamiento y prevenir la expansión del virus. Universidades, instituciones del estado y organizaciones de sociedad civil han hecho llamados a decenas de Hackatones con el fin de encontrar soluciones de este tipo.
El contexto puede variar un poco pero la idea es más o menos la misma en todas las convocatorias: crear una app que ubique y permita hacer tracking del desplazamiento de las personas. Así, cuando un usuario de dicha app es diagnosticado positivo, el historial de sus ubicaciones anteriores podría ayudar a determinar el riesgo de contagio en diferentes zonas de la ciudad y alertar a las personas con las que el contagiado tuvo contacto. También podría alertar a los demás usuarios cuándo están cerca de una zona de alto riesgo de contagio por la confluencia de contagiados.
El razonamiento anterior parece sencillo, pero su implementación está lejos de serlo. A propósito de la nueva estrategia de geolocalización creada por el Estado a través del grupo “Te Cuido Perú” o la aplicación “Perú en tus Manos.” resulta más relevante que nunca conocer los límites técnicos de esta idea. ¿Realmente el seguimiento y geolocalización de las personas ayudará a reducir la cantidad de infectados en el Perú?¿Nos ayudaría a retomar nuestras actividades normales después de la cuarentena? De ser así, ¿Cuál sería la tecnología más adecuada para realizarlos? ¿Qué medidas deberían tomarse para que se respete nuestra privacidad?